[This is cross-posted from my general blog: https://grampsgrumps.blogspot.com/.]
Subtyping fits naturally with our human view of reality. Consider these sets of individuals: Dogs, Cats, Humans, Crocodiles, Mammals, Quadrupeds, Animals. There is a natural relation between them represented by this diagram:
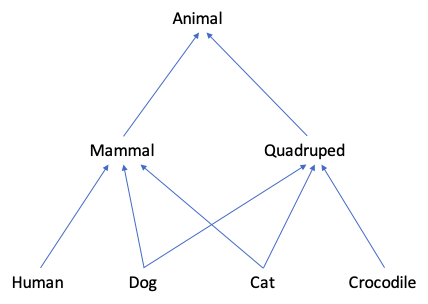
At a simple level these are just sets of individuals and the arrows represent set inclusion. But clearly there is more to it than that. The Dog type is distinguished by properties that let us identify an individual as being a dog. And we can see that there is a symmetry in the diagram. As we go up we get more and more individuals in the type, but as we go down we get more and more properties.
This perfectly natural form of subtyping is the right way to do subtyping in a computer programming language.
Now imagine a box that always has a dog in it, and we can change the dog inside to any other dog. Nobody would think that the type of such boxes was a subtype of boxes that have a mammal in it and we can change the contents to any other mammal. The mammal box isn't a dog box because it might have a non-dog inside, and a dog box isn't a mammal box because it isn't big enough for all mammals. They are just different.
Computer memory is like those boxes. Consider 16 bit integers. They can be naturally seen as a subtype of 32 bit integers, since every such can be represented in 32 bits, and 16 bit integers have the property that the integer fits in 16 bits. We can look at a 32 bit integer and decide if it fits in 16 bits. Now consider memory locations that have enough space for a 16 bit integer. These can't be used if what you want is a memory location that can hold a 32 bit integer. And the reverse is equally true: if you have a memory location with a 32 bit integer in it, then you can't use it where you expect a memory location with a 16 bit integer. Once again, they're just different.
Because computers work with changeable memory locations, many programming languages conflate values, such as integers, with boxes which can hold such a value. The first object oriented programming language was Simula 67 and it had classes that consisted of multiple memory-like boxes. It had subclasses which were a brilliant innovation, but they didn't work as we naturally expect, and that has been leading programmers astray, causing bugs, ever since.
Functional programming style emphasizes values rather than places for changing values. These value types naturally form a subtyping hierarchy that behaves the way humans expect. And it turns out that if you organise your type hierarchy correctly a lot of magical goodness results.
The rest of this post will get more technical, and belongs in my programming blog (https://wombatlang.blogspot.com/) where it will also be posted.
Types in our programming language arise in various ways that we won't consider here. They come in indexed families, giving some of the functionality of Dependent Types. So Vect(15,Int) represents a sequence of 15 Ints. Vect is the base type and it is indexed by a tuple of an Int and a Type, i.e. by a Tuple(Int,Type). Every value has a Type, and given a type we can find its base type and its index.
Types can be empty, with no values. Indeed this is common, because one of the most immediate uses of indexed types is for types representing propositions. This is relevant because the properties we want our types to have are often propositions. As an example, the Int type has a property "add" which is a procedure taking two Ints and returning an Int (add has type Int*Int=>Int). Another property says that add is commutative, and this has type forall Int x,y: add(x,y)==add(y,x). So properties are just named values. The naming scheme allows us to identify when types share variants of the same property.
We are comfortable with the idea that something of type Dog is also of type Mammal. However in a programming language it is more natural to say that there is an embedding of the lower type in the higher. An embedding is a pair of procedures, one upward from the smaller type and the other from the larger to the smaller. The upward procedure always succeeds (we say it is "total"), but the downward procedure will fail if the input value doesn't have a corresponding value in the smaller type. The two procedures are inverses where they are both defined.
Rather than introduce new, more computerish types, I'll just keep the type names from our earlier real world example.
We declare a subtyping relation with an isa declaration that specifies the up and down procedures. We might also need to help the compiler prove that they are inverses. So we have Dog isa Mammal and Dog isa Quadruped. We automatically extend the subtyping so that if X isa Y and Y isa Z then we also have X isa Z. In our example we then have Dog isa Animal. Mathematically we now have a partial order (assuming the trivial rule that X isa X). Then we add the key rule from our real world types: lower types inherit all the properties from higher types. Thus the Dog type has all the properties of the Mammal type and of the Quadruped type, as well as additional Dog-specific properties.
We now see that a dog, i.e. a value of type Dog, can get converted upwards to Animal in 2 different ways. It is essential that both routes lead to the same value of type Animal. That doesn't mean that the two routes have to get to the same value as a string of bits. It just means that an equality check will pass and whichever choice is used in code one gets the same effects and result.
The reader might be beginning to suspect that this is not going to be as easy as it looked at first. And, indeed, it is about to get a lot harder. In our real world example the entities (animals) involved are collections of atoms, and their distinguishing properties are about how those atoms are arranged. It is tempting to think that the entities in programming are collections of bits, but that leads us astray, because we want the same bits to mean different things, depending on the type and its properties. The bits are just a means to an end. The values we want are mathematical entities of different types, and the properties of that type tell us what we can do with them. So it is not surprising that a correct subtyping scheme is based on mathematical ideas.
If you have a set of elements in a partial order, then an upper bound is any element that is above all of them. A partial order is called a lattice (or an "order lattice") if every set of elements has a least upper bound and a greatest lower bound. An important case is sets ordered by set inclusion, for which the least upper bound is just the union of those sets (of sets), and the greatest lower bound is the intersection.
We now expand our subtyping scheme to an order lattice. The proposed scheme makes our types behave very like sets, so it is natural to name the constructs Union and Intersection. It works like this:
- If X isa Y then Union(X,Y)=Y and Intersection(X,Y)=X.
- Otherwise the values of Union(X,Y) are the values of X and the values of Y plus an indication of which they came from. The properties are those inherited from types that are above both.
- The properties of Intersection(X,Y) are the properties of either. The values are the combined values (i.e. the Union) of all types that are below both.
- The generalization to sets of other than 2 types is mostly straightforward. A particular case is the empty set: Union() is Empty, the bottom type with no values but all properties; and Intersection() is Any, the top type with all values and no properties except downward conversion.
So here is our diagram with some of the new types:
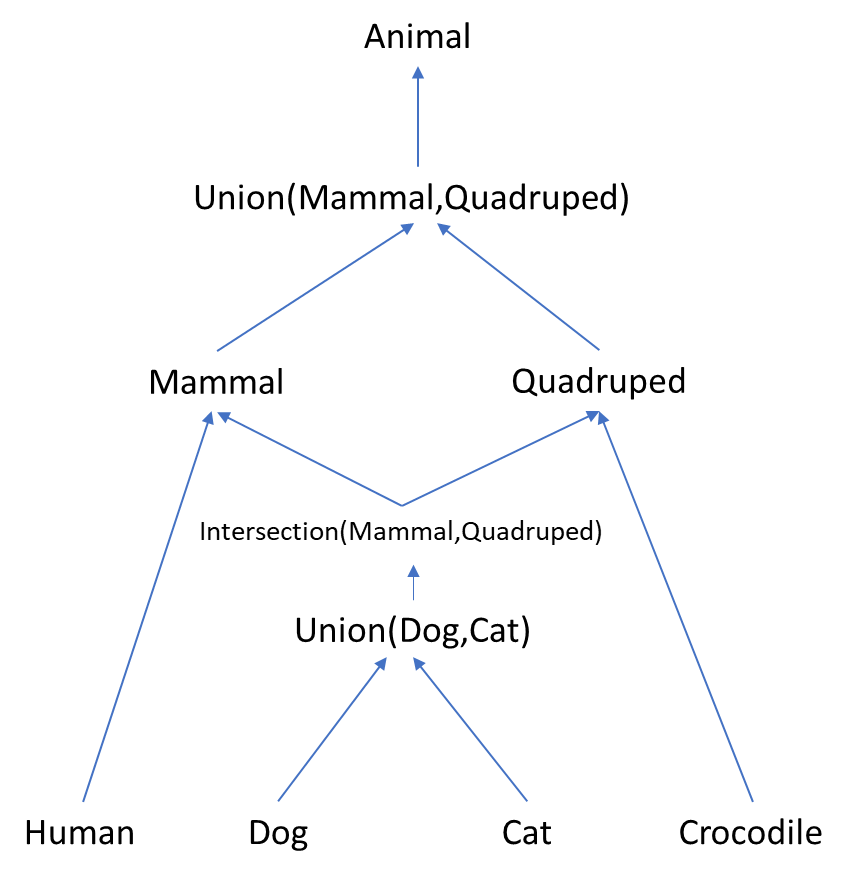
The arrows shown to and from the unions and the intersection are automatically generated from the arrows defined as in the earlier diagram. To test equality in a Union we take the 2 downward links to their origin types, then the downward links to the Intersection of the two types and check equality there. Of course the values there come from another Union (of types below both) so we repeat. This is not a problem in practice. Creating an infinite regress is left as an exercise for the reader.
Another way of creating types is as subset types. This comes from an existing type and a subsetting predicate. The values of this type are those matching the predicate, and the properties are those of the base type. Two important examples are the singleton subset where the predicate picks out one value, and the empty subset where there are no values. These are the types you get when a calculation succeeds or fails respectively.
There is a lot more to say, but only on the technical blog: https://wombatlang.blogspot.com/.
No comments:
Post a Comment